Developing microblx blocks¶
Overview¶
Generally, building a block entails the following:
- declaring configuration: what is the static configuration of a block
- declaring ports: what is the input/output of a block
- declaring types: which data types are communicated
- declaring block meta-data: provide further information about a block
- declaring and implementing hook functions: how is the block
initialized, started, run, stopped and cleaned up?
- reading configuration values: how to access configuration from inside the block
- reading and writing from ports: how to read and write from ports
- declaring the block: how to put everything together
- registration of blocks and types: make block prototypes and types known to the system
The following describes these steps in detail and is based on the
(heavily) documented random number generator block
(std_blocks/random/).
Note: Instead of manually implementing the above, a tool
ubx_genblock is available which can generate blocks including
interfaces from a simple description. See Block code-generation.
Declaring configuration¶
Configuration is described with a NULL terminated array of
ubx_config_t types:
ubx_config_t rnd_config[] = {
{ .name="min_max_config", .type_name = "struct random_config" },
{ NULL },
};
The above defines a single configuration called “min_max_config” of the type “struct random_config”.
Note:: custom types like struct random_config must be registered
with the system. (see section “declaring types”)
To reduce boilerplate validation code in blocks, min and max
attributes can be used to define permitted length of configuration
values. For example:
ubx_config_t rnd_config[] = {
{ .name="min_max_config", .type_name = "struct random_config", .min=1, .max=1 },
{ NULL },
};
Would require that this block must be configured with exactly one
struct random_config value. Checking will take place before the
transition to inactive (i.e. before init).
In fewer cases, configuration takes place in state inactive and
must be checked before the transition to active. That can be
achieved by defining the config attribute CONFIG_ATTR_CHECKLATE.
Legal values of min and max are summarized below:
| min | max | result |
|---|---|---|
| 0 | 0 | no checking (disabled) |
| 0 | 1 | optional config |
| 1 | 1 | mandatory config |
| 0 | CONFIG_LEN_MAX | zero to many |
| 0 | undefined | zero to many |
| N | M | must be between N and M |
Declaring ports¶
Like configurations, ports are described with a NULL terminated
array of ubx_config_t types:
ubx_port_t rnd_ports[] = {
{ .name="seed", .in_type_name="unsigned int" },
{ .name="rnd", .out_type_name="unsigned int" },
{ NULL },
};
Depending on whether an in_type_name, an out_type_name or both
are defined, the port will be an in-, out- or a bidirectional port.
Declaring block meta-data¶
char rnd_meta[] =
"{ doc='A random number generator function block',"
" realtime=true,"
"}";
Additional meta-data can be defined as shown above. The following keys are supported so far:
doc:short descriptive documentation of the blockrealtime: is the block real-time safe, i.e. there are is no memory allocation / deallocation and other non deterministic function calls in thestepfunction.
Declaring/implementing block hook functions¶
The following block operations can be implemented to realize the blocks behavior. All are optional.
int rnd_init(ubx_block_t *b);
int rnd_start(ubx_block_t *b);
void rnd_stop(ubx_block_t *b);
void rnd_cleanup(ubx_block_t *b);
void rnd_step(ubx_block_t *b);
These functions can be called according to the microblx block life-cycle finite state machine:
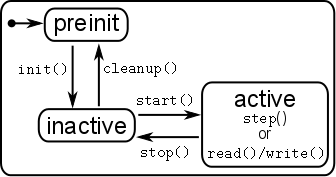
Block lifecycle FSM
They are typically used for the following:
init: initialize the block, allocate memory, drivers: check if the device is there and return non-zero if not.start: become operational, open device, last checks. Cache pointers to ports, read configuration.step: read from ports, compute, write to portsstop: stop/close device. (often not used).cleanup: free all memory, release all resources.
Storing block local state¶
As multiple instances of a block may exists, NO global variables may
be used to store the state of a block. Instead, the ubx_block_t
defines a void* private_data pointer which can be used to store
local information. Allocate this in the init hook:
if ((b->private_data = calloc(1, sizeof(struct random_info)))==NULL) {
ubx_err(b, "Failed to alloc memory");
goto out_err;
}
and retrieve it in the other hooks:
struct block_info inf*;
inf = (struct random_info*) b->private_data;
Reading configuration values¶
The following example from the random block shows how to retrieve a
struct configuration called min_max_config:
long int len;
struct random_config* rndconf;
/*...*/
if((len = ubx_config_get_data_ptr(b, "min_max_config", &rndconf)) < 0)
goto err;
if(len==0)
/* set a default or fail */
ubx_config_get_data_ptr returns the pointer to the actual data.
len will be set to the array lenghth: 0 if unconfigured, >0 if
configured and <0 in case of error.
For basic types there are several predefined and somewhat type safe
convenience functions cfg_getptr_*. For example, to retrieve a
scalar uint32_t and to use a default 47 if unconfigured:
long int len;
uint32_t *value;
if ((len = cfg_getptr_int(b, "myconfig", &value)) < 0)
goto out_err;
value = (len > 0) ? *value : 47;
When to read configuration: init vs start?¶
It depends: if needed for initalization (e.g. a char array describing
which device file to open), then read in init. If it’s not needed in
init (e.g. like the random min-max values in the random block
example), then read it in start.
This choice affects reconfiguration: in the first case the block has to
be reconfigured by a stop, cleanup, init, start
sequence, while in the latter case only a stop, start sequence
is necessary.
Reading from and writing to ports¶
The following helper macros are available to support
def_read_fun(read_uint, unsigned int)
def_write_fun(write_uint, unsigned int)
Declaring the block¶
The block aggregates all of the previous declarations into a single data-structure that can then be registered in a microblx module:
ubx_block_t random_comp = {
.name = "random/random",
.type = BLOCK_TYPE_COMPUTATION,
.meta_data = rnd_meta,
.configs = rnd_config,
.ports = rnd_ports,
/* ops */
.init = rnd_init,
.start = rnd_start,
.step = rnd_step,
.cleanup = rnd_cleanup,
};
Declaring types¶
All types used in configurations and ports must be declared and registered. This is necessary because microblx needs to know the size of the transported data. Moreover, it enables type reflection which is used by logging or the webinterface.
In the random block example, we used a struct random_config, that is
defined in types/random_config.h:
struct random_config {
int min;
int max;
};
It can be declared as follows:
#include "types/random_config.h"
#include "types/random_config.h.hexarr"
ubx_type_t random_config_type = def_struct_type(struct random_config, &random_config_h);
This fills in a ubx_type_t data structure called
random_config_type, which stores information on types. Using this
type declaration the struct random_config can then be registered
with a node (see “Block and type registration” below).
What is this .hexarr file?
The file types/random_config.h.hexarr contains the contents of the
file types/random_config.h converted to an array
const char random_config_h [] using the tool tools/ubx_tocarr.
This char array is stored in the ubx_type_t private_data field (the
third argument to the def_struct_type macro). At runtime, this type
model is loaded into the luajit ffi, thereby enabling type reflection
features such as logging or changing configuration values via the
webinterface. The conversion from .h to .hexarray is done via a
simple Makefile rule.
This feature is optional. If no type reflection is needed, don’t include
the .hexarr file and pass NULL as a third argument to
def_struct_type.
Block and type registration¶
So far we have declared blocks and types. To make them known to the system, these need to be registered when the respective module is loaded in a microblx node. This is done in the module init function, which is called when a module is loaded:
1: static int rnd_module_init(ubx_node_info_t* ni)
2: {
3: ubx_type_register(ni, &random_config_type);
4: return ubx_block_register(ni, &random_comp);
5: }
6: UBX_MODULE_INIT(rnd_module_init)
Line 3 and 4 register the type and block respectively. Line 6 tells
microblx that rnd_module_init is the module’s init function.
Likewise, the module’s cleanup function should deregister all types and blocks registered in init:
static void rnd_module_cleanup(ubx_node_info_t *ni)
{
ubx_type_unregister(ni, "struct random_config");
ubx_block_unregister(ni, "random/random");
}
UBX_MODULE_CLEANUP(rnd_module_cleanup)
Using real-time logging¶
Microblx provides logging infrastructure with loglevels similar to the
Linux Kernel. Loglevel can be set on the (global) node level (e.g. by
passing it -loglevel N to ubx_launch or be overridden on a per
block basis. To do the latter, a block must define and configure a
loglevel config of type int. If it is left unconfigured, again
the node loglevel will be used.
The following loglevels are supported:
UBX_LOGLEVEL_EMERG(0) (system unusable)UBX_LOGLEVEL_ALERT(1) (immediate action required)UBX_LOGLEVEL_CRIT(2) (critical)UBX_LOGLEVEL_ERROR(3) (error)UBX_LOGLEVEL_WARN(4) (warning conditions)UBX_LOGLEVEL_NOTICE(5) (normal but significant)UBX_LOGLEVEL_INFO(6) (info message)UBX_LOGLEVEL_DEBUG(7) (debug messages)
The following macros are available for logging from within blocks:
ubx_emerg(b, fmt, ...)
ubx_alert(b, fmt, ...)
ubx_crit(b, fmt, ...)
ubx_err(b, fmt, ...)
ubx_warn(b, fmt, ...)
ubx_notice(b, fmt, ...)
ubx_info(b, fmt, ...)
ubx_debug(b, fmt, ...)
Note that ubx_debug will only be logged if UBX_DEBUG is defined
in the respective block and otherwise compiled out without any overhead.
To view the log messages, you need to run the ubx_log tool in a
separate window.
Important: The maximum total log message length (including is by default set to 80 by default), so make sure to keep log message short and sweet (or increase the lenghth for your build).
Note that the old (non-rt) macros ERR, ERR2, MSG and DBG
are deprecated and shall not be used anymore.
Outside of the block context, (e.g. in module_init or
module_cleanup, you can log with the lowlevel function
ubx_log(int level,
ubx_node_info_t *ni,
const char* src,
const char* fmt, ...)
/* for example */
ubx_log(UBX_LOGLEVEL_ERROR, ni, __FUNCTION__, "error %u", x);
e.g.
The ubx core uses the same logger, but mechanism, but uses the
log_info resp logf_info variants. See libubx/ubx.c for
examples.
SPDX License Identifier¶
Microblx uses a macro to define module licenses in a form that is both machine readable and available at runtime:
UBX_MODULE_LICENSE_SPDX(MPL-2.0)
To dual-license a block, write:
UBX_MODULE_LICENSE_SPDX(MPL-2.0 BSD-3-Clause)
Is is strongly recommended to use this macro. The list of licenses can be found on http://spdx.org/licenses
Block code-generation¶
The ubx_genblock tool generates a microblx block including a
Makefile. After this, only the hook functions need to be implemented
in the .c file:
Example: generate stubs for a myblock block (see
examples/block_model_example.lua for the block generator model).
$ ubx_genblock -d myblock -c /usr/local/share/ubx/examples/blockmodels/block_model_example.lua
generating myblock/bootstrap
generating myblock/configure.ac
generating myblock/Makefile.am
generating myblock/myblock.h
generating myblock/myblock.c
generating myblock/myblock.usc
generating myblock/types/vector.h
generating myblock/types/robot_data.h
Run ubx_genblock -h for full options.
The following files are generated:
bootstrapautoconf bootstrap scriptconfigure.acautoconf input fileMakefile.amautomake input filemyblock.hblock interface and module registration code (don’t edit)myblock.cmodule body (edit and implement functions)myblock.uscsimple microblx system composition file, see below (can be extended)types/vector.hsample type (edit and fill in struct body)robot_data.hsample type (edit and fill in struct body)
If the command is run again, only the .c file will NOT be
regenerated. This can be overridden using the -force option.
Compile the block¶
$ cd myblock/
$ ./bootstrap
$ ./configure
$ make
$ make install
Launch block using ubx_launch¶
$ ubx_ilaunch -webif -c myblock.usc
Run ubx_launch -h for full options.
Browse to http://localhost:8888
Tips and Tricks¶
Using C++¶
See std_blocks/cppdemo. If the designated initializer (the struct
initalization used in this manual) are used, the block must be
compiled with clang, because g++ does not support designated
initializers (yet).
Avoiding Lua scripting¶
It is possible to avoid the Lua scripting layer entirely. A small
example can be found in examples/c-only.c. See also the
tutorial for a more complete example.
Speeding up port writing¶
To speed up port writing, the pointers to ports can be cached in the
block info structure. The ubx_genblock script automatically takes
care of this.
What the difference between block types and instances?¶
First: to create a block instance, it is cloned from an existing block
and the block->prototype char pointer set to a newly allocated string
holding the protoblocks name.
There’s very little difference between prototypes and instances:
- a block type’s
prototype(char) ptr isNULL, while an instance’s points to a (copy) of the prototype’s name. - Only block instances can be deregistered and freed
(
ubx_block_rm), prototypes must be deregistered (and freed if necessary) by the module’s cleanup function.
Module visibility¶
The default Makefile defines -fvisibility=hidden, so there’s no need
to prepend functions and global variables with static